تقسیم بندی معنایی-مهندس اتومبیل خودران Udaity نانو درجه

این پروژه از مفاهیم یادگیری عمیقی که در دوره اول نانو درجه Udacity آموخته شده استفاده می کند. این مقاله یکی از مفاهیم مهم در بینایی رایانه ، تقسیم بندی معنایی را توضیح داده و پیاده سازی می کند.
1. تقسیم بندی معنایی
برای چند دهه تقسیم بندی تصویر یک کار پیچیده در بینایی رایانه بود. اکنون با یادگیری عمیق آسان تر شده است. تقسیم بندی تصویر با طبقه بندی تصویر متفاوت است. در طبقه بندی تصویر ، فقط اشیایی را که دارای برچسب های خاص مانند اسب ، اتومبیل ، خانه و غیره است طبقه بندی می کند که در آن الگوریتم تقسیم بندی تصاویر نیز اشیاء ناشناخته را تقسیم بندی می کند. تقسیم بندی تصویر نیز به عنوان تقسیم بندی معنایی شناخته می شود. این پیوند تفاوت عمده بین طبقه بندی و تقسیم بندی را به خوبی توضیح می دهد.
تقسیم بندی معنایی درک یک تصویر در سطح پیکسل است. به عبارت دیگر ، هر پیکسل به یک کلاس خاص در تصویر اختصاص داده شده است.

تصویر اصلی (منبع)
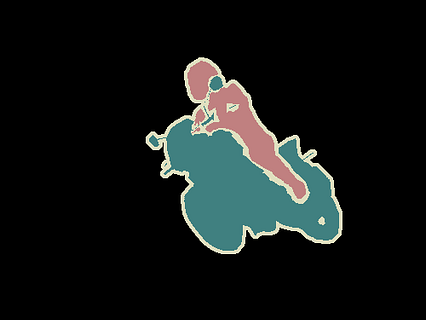
بعد از تقسیم بندی (منبع)
قبل از تأثیر یادگیری عمیق در بینایی رایانه ، سایر روشهای یادگیری ماشین مانند جنگل تصادفی که برای تقسیم بندی استفاده می شد.
اخیراً ، شبکه عصبی کانولوشن (CNN) در طبقه بندی تصویر در گذشته.
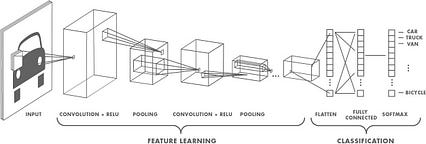
CNN
در ساختار معمولی CNN ، لایه ورودی و سپس لایه کانولوشن ، سپس برای طبقه بندی تصویر به لایه کاملاً متصل به دنبال softmax متصل می شود. CNN باید طبقه بندی کند که آیا تصویر دارای شیء خاصی است ، اما پاسخ دادن به اینکه "شی در تصویر کجاست" دشوارتر است. این به این دلیل است که لایه کاملاً متصل اطلاعات مکانی را حفظ نمی کند. مدل زیر راه حل مشکل فضایی با لایه های متصل است.
شبکه کاملاً متحول (FCN)
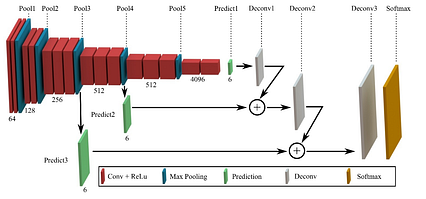
FCN
لایه تجمع نیز یکی از مشکلات اصلی است ، جدا از لایه کاملاً متصل ، در CNN برای حفظ اطلاعات فضایی. لایه جمع آوری می تواند زمینه را جمع آوری کرده و اطلاعات "کجا" را کنار بگذارد. اما در تقسیم بندی معنایی ، ما باید زمینه "where" را حفظ کنیم تا هر پیکسل را به کلاس شی مربوطه ترسیم کنیم.

FCN
به منظور مقابله با این موضوع از معماری رمزگشای-رمزگشایی استفاده می شود که در آن رمزگذار بتدریج بعد فضایی را با ترکیب لایه ها کاهش می دهد و رمزگشا به تدریج جزئیات شی و ابعاد فضایی را بازیابی می کند. به همچنین از پرش از اتصالات رمزگذار به رمزگشا برای کمک به رمزگشایی بهتر بازیابی جزئیات شی استفاده کنید.
همانطور که در تصویر بالا نشان داده شده است ، FCN یکی از آن نوع معماری است که لایه کاملاً متصل را با رمزگشا جایگزین می کند.
رمزگذار
این شامل لایه های کانولوشن است که به جای لایه های کاملاً متصل به هم ، یک لایه پیچشی 1x1 متصل شده اند. در حقیقت ، بسیاری از مدلهای FCN از پیاده سازی FCN-8 برگرفته از این مقاله
رمزگذار FCN-8 مدل VGG16 است که برای طبقه بندی بر روی ImageNet از قبل آموزش داده شده است.
رمزگشایی
رمزگشایی قسمت دوم FCN است که در آن خروجی رمزگذار را با استفاده از مجموعه ای از پیچیدگی های جابجا شده نمونه برداری می کنیم.
اجرای معمولی یک لایه نمونه برداری به شرح زیر است:
output = tf .layers.conv2d_transpose (input، num_classes، 4، strides = (2، 2))
لایه های متحرک جابجایی ابعاد ارتفاع و عرض تنسور ورودی 4 بعدی را افزایش می دهند.
رد شدن اتصال
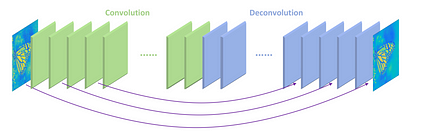
منبع: https://stackoverflow.com/questions/45976166/loss -notololing-when-use-skip-connections
اتصال پرش راهی برای حفظ اطلاعات از بین رفته از طریق رمزگذار است. خروجی لایه یکپارچه سازی از رمزگذار همراه با خروجی رمزگشایی لایه اول با استفاده از یک عملیات افزودن عاقلانه. سپس به آن تغذیه می شودلایه بعدی رمزگشایی در نتیجه ، شبکه می تواند تصمیمات دقیق تری برای تقسیم بندی اتخاذ کند. /p>
# مطمئن شوید که شکل ها یکسان هستند!
skip1 = tf.add (conv_1x1_4th_layer، upsampling1، name = "skip1")
سپس می توانیم این کار را با یک لایه متحرک دیگر منتقل کنیم.
upsampling2 = tf.layers.conv2d_transpose (skip1 ، num_classes، 4، strides = (2، 2)، padding = 'same'، kernel_regularizer = tf.contrib.layers.l2_regularizer (1e-3)، name = 'upsampling2')
ما این کار را با خروجی لایه سوم جمع آوری مجدد تکرار کنید.
skip2 = tf.add (conv_1x1_3th_layer، upsampling2، name = "skip2")
طبقه بندی و ضرر
آخرین توقف تعریف ضرر است که به ما در آموزش FCN کمک می کند درست مانند آموزش در CNN.
هدف FCN این است که هر پیکسل را به کلاس مناسب اختصاص دهد. ما می توانیم از روش از دست دادن آنتروپی متقابل مشابه CNN استفاده کنیم.
قبل از تغذیه با تابع از دست دادن آنتروپی متقاطع ، تانسور خروجی 4 بعدی است ، بنابراین ما باید آن را به 2 بعدی تغییر دهیم. همچنین برچسب ما باید مانند logits تغییر شکل دهد.
logits = tf.reshape (ورودی ، (-1 ، num_classes))
label_reshaped = tf.reshape (correct_label، (-1، num_classes))
logits و labels اکنون یک تنسور دو بعدی هستند که در آن هر سطر یک پیکسل و هر ستون یک کلاس را نشان می دهد. سپس ما می توانیم هر دو را در تابع ضرر به شرح زیر وارد کنیم: پیاده سازی
این پروژه بر اساس FCN8 است که از VGG16 به عنوان رمزگذار استفاده می کند. اولین قدم این است که مدل بارگیری شده VGG16 را بارگذاری کنید.
مدل VGG16 وانیلی نیست ، بلکه یک نسخه کاملاً متحرک است که قبلاً شامل پیچهای 1x1 برای جایگزینی لایه های کاملاً متصل شده است. سپس لایه VGG را بارگذاری می کنیم تا ورودی_پایه ، لایه 3 ، لایه 4 و لایه 7 را با استفاده از تابع load_vgg که به عنوان بخشی از پروژه تعریف کردیم بارگذاری کنیم.
input_layer، keep_prob_tensor، layer3، layer4، layer7 = load_vgg (sess، vgg_path)
هنگامی که لایه های فوق را از VGG19 دریافت کردیم ، سپس قسمت دوم FCN ، رمزگشایی را تعریف می کنیم. در رمزگشایی ، ما باید خروجی لایه های فوق را به کانولوشن 1x1 تبدیل کرده و سپس با استفاده از کانولوشن جابجا شده نمونه برداری کنیم. همچنین ما اتصال پرش را به عنوان بخشی از این تابع تعریف می کنیم. ما این عملکردها را تحت توابع لایه ها به شرح زیر تعریف می کنیم:
لایه های def (vgg_layer3_out ، vgg_layer4_out ، vgg_layer7_out ، num_classes):
"" "
لایه ها را برای یک شبکه کاملاً متحرک ایجاد کنید. با استفاده از لایه های vgg لایه های پرش ایجاد کنید.
: param vgg_layer3_out: TF Tensor برای خروجی VGG Layer 3
: param vgg_layer4_out: TF Tensor برای خروجی VGG Layer 4
: param vgg_layer7_out: TF Tensor برای خروجی VGG Layer 7
: param num_classes: تعداد کلاسهایی که باید طبقه بندی شوند
: return: Tensor برای آخرین لایه خروجی
"" "
همگرایی # 1X1 لایه 7
conv_1x1_7th_layer = tf.layers.conv2d (vgg_layer7_out ، num_classes ، 1 ، padding = 'same'،
kernel_regularizer = tf.contrib.layers.l2_regularizer (1e-3) ،name = 'conv_1x1_7th_layer')
# Upsampling x 4
upsampling1 = tf.layers.conv2d_transpose (conv_1x1_7th_layer,
num_classes,
4,
strides = (2, 2),
padding = 'same',
kernel_regularizer = tf.contrib.layers.l2_regularizer (1e-3),
name = 'upsampling1')
# 1X1 convolution of the layer 4
conv_1x1_4th_layer = tf.layers.conv2d (vgg_layer4_out,
num_classes,
1,
padding = 'same',
kernel_regularizer = tf.contrib.layers.l2_regularizer (1e-3),نام = 'conv_1x1_4th_layer')
skip1 = tf.add (conv_1x1_4th_layer، upsampling1، name = "skip1")
# Upsampling x 4
upsampling2 = tf.layers.conv2d_transpose (skip1،
num_classes ،
4 ،
گامها = (2 ، 2) ،
padding = 'same'،
kernel_regularizer = tf.contrib.layers.l2_regularizer (1e-3) ،
نام = 'upsampling2')
کانولوشن # 1X1 لایه 3
conv_1x1_3th_layer = tf.layers.conv2d (vgg_layer3_out ،
num_classes ،
1 ،
padding = 'same'،
kernel_regularizer = tf.contrib.layers.l2_regularizer (1e-3) ،
نام = 'conv_1x1_3th_layer')
skip2 = tf.add (conv_1x1_3th_layer، upsampling2، name = "skip2")
# Upsampling x 8.
upsampling3 = tf.layers.conv2d_transpose (skip2 ، num_classes ،16 ،
گامها = (8 ، 8) ،
padding = 'same'،
kernel_regularizer = tf.contrib.layers.l2_regularizer (1e-3) ،
نام = 'upsampling3')
return upsampling3 سپس تابع بهینه سازی را تعریف می کنیم که در آن از دست دادن آنتروپی و بهینه ساز corss تعریف می شود
"" "
عملیات تلفات و بهینه ساز TensorFLow را بسازید.
: param nn_last_layer: TF Tensor لایه آخر در شبکه عصبی
: param correct_label: TF Placeholder برای تصویر برچسب صحیح
: param learning_rate: TF Placeholder برای میزان یادگیری
: param num_classes: تعداد کلاسهایی که باید طبقه بندی شوند
: return: تعدادی از (logits ، train_op ، cross_entropy_loss)
"" "
# TODO: تابع پیاده سازی
# برچسب را مانند logits تغییر دهید
label_reshaped = tf.reshape (label_ correct، (-1، num_classes))
# تبدیل تانسور 4 بعدی به دو طرفه. logits اکنون یک تانسور دو بعدی است که در آن هر سطر یک پیکسل و هر ستون یک کلاس را نشان می دهد
logits = tf.reshape (nn_last_layer ، (-1 ، num_classes))
# نام logits Tensor ، به طوری که می تواند پس از آموزش از دیسک بارگیری شود
logits = tf.identity (logits، name = ’logits’)
# ضرر و بهینه ساز
cross_entropy_loss = tf.reduce_mean (tf.nn.softmax_cross_entropy_with_logits (logits = logits، labels = label_reshaped))
reg_losses = tf.get_collection (tf.GraphKeys.REGULARIZATION_LOSSES)
reg_constant = 1e-3
ضرر = تلفات_تروپی_متقابل + reg_constant * مبلغ (reg_losses)
train_op = tf.train.AdamOptimizer (میزان یادگیری = میزان یادگیری) .کاهش (از دست دادن)
logits return، train_op، loss
آخرین مرحله برای آموزش مدل ، تعریف پارامترهای فوق و حلقه زدن تصاویر از طریق عملکرد ذکر شده در بالا است.
sess.run (tf.global_variables_initializer () )
# چرخه آموزش
برای دوره در محدوده (دوره ها):
چاپ (قالب "دوران"} (دوره +1))ضرر_آموزشی = 0
Training_samples_length = 0
برای تصویر ، برچسب در get_batches_fn (batch_size):
Training_samples_length += len (تصویر)
_، loss = sess.run ([train_op، cross_entropy_loss]، feed_dict = {
input_image: image،
correct_label: label،
keep_prob: 0.5 ،
نرخ یادگیری: 0.0001
})
آموزش_از دست دادن += باخت
چاپ (از دست دادن)
# از دست دادن کل تمرین
training_loss /= training_samples_length
چاپ ("******************** کل ضرر **********************")
print (training_loss) پارامترهای فوق العاده ای که در نهایت انتخاب می کنیم Epochs = 50 و batch_size = 5 است.
در اینجا چند تصویر است که برای تقسیم بندی تصویر به کار گرفته شده است. لطفاً به خاطر داشته باشید ، ما فقط دو کلاس را در نظر می گیریم: جاده یا جاده.



3. چالش اختیاری
چالش این بود که مدل آموزش دیده را روی یک ویدئو بکار ببرید تا ویدئویی از تقسیم بندی معنایی ایجاد شود. من فرصتی برای انجام این کار ندارم ، اما روند بسیار ساده است ، زیرا قبلاً در فصل 1 آموختیم که چگونه ویدیو را با اعمال جلوه در هر فریم از ویدئو ایجاد کنیم. در این سناریوی خاص ، ما باید مدل ذخیره شده را بارگذاری کرده و مدل را در هر فریم از ویدیو اعمال کنیم. سرانجام فریم ها را با هم ترکیب کنید تا از تقسیم بندی معنایی فیلم تهیه کنید.
این تقریباً همینطور است. اگر می خواهید کد را در عمل ببینید ، لطفاً از repo github دیدن کنید.
اگر نوشتن من را دوست دارید ، من را در Github ، Linkedin و/یا نمایه متوسط دنبال کنید.
مرجع
مهندس اتومبیل خودران Udacity nanodegree http://blog.qure.ai/notes/semantic-segmentation-deep-learning-review https://www.quora.com/تفاوت-بین-طبقه بندی-تصویر-و-تشخیص-https://people.eecs.berkeley.edu/~jonlong /long_shelhamer_fcn.pdf تجربه ای در واگن قطار
[ بازدید : 15 ] [ امتیاز : 3 ] [ نظر شما :
]
 عکس ارنست اوژه در Unsplash
عکس ارنست اوژه در Unsplash  منبع
منبع  "ماشین سبز قدیمی در جاده ”توسط Court Prather on Unsplash
"ماشین سبز قدیمی در جاده ”توسط Court Prather on Unsplash 





 < p> به طور معمول ، من 2020 را با نگاهی به پیش بینی هایی که در ابتدای سال 2020 داشتم ، به پایان می رسانم. به جز ... من هیچ پیش بینی ای در ابتدای سال 2020 نکردم. من یک سال را حذف کردم ، بنابراین مجبورم دو سال به عقب بازگردید تا به پیش بینی هایی که در ابتدای سال 2019 انجام دادم ، نگاهی بیندازید.
< p> به طور معمول ، من 2020 را با نگاهی به پیش بینی هایی که در ابتدای سال 2020 داشتم ، به پایان می رسانم. به جز ... من هیچ پیش بینی ای در ابتدای سال 2020 نکردم. من یک سال را حذف کردم ، بنابراین مجبورم دو سال به عقب بازگردید تا به پیش بینی هایی که در ابتدای سال 2019 انجام دادم ، نگاهی بیندازید. 
 عکس توسط شوهر نویسنده گرفته شده است.
عکس توسط شوهر نویسنده گرفته شده است.  < p> شریک ما LeEco به تازگی خودروی مفهومی LeSEE خود را در سان فرانسیسکو رونمایی کرد.
< p> شریک ما LeEco به تازگی خودروی مفهومی LeSEE خود را در سان فرانسیسکو رونمایی کرد.  عکس توسط امیلیانو ویتوریوسی در Unsplash
عکس توسط امیلیانو ویتوریوسی در Unsplash